这篇文章介绍一下我们最近的一项工作:
A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics (arXiv)

在现代深度学习中,自监督学习(SSL)通过从无标签数据中提取结构化信息,展现了强大的泛化能力。其核心目标是学习到一个良好的表征几何(Representation Geometry),使得相似的输入在空间中聚集,不同的输入保持距离。
然而,在这一过程中,我们常常会观察到一个被称为表征坍塌(Representation Collapse)的失效模式:表征失去了区分度,原本不同的数据点在表征空间中收缩、重合,导致模型完全失效。
尽管工程上已经发展出了多种避免坍塌的技术手段,但其底层的动力学机制依然缺乏清晰的理解。在最近的这项工作中,我们尝试跳出传统的分析框架,剥离具体的神经网络模型架构与参数细节,直接在表征空间构建一个极简的动力学模型。在这个视角中,我们发现可以通过统计物理中的一个经典概念——阻挫(Frustration),来建模和解释表征坍塌的核心机制。
现象观察:时间尺度上的反常表现
在切入理论模型之前,我们先审视一个具体的训练现象。
区别于标准分类任务中的设定,我们采用了一种生成式的表征学习框架:将数据和标签分别映射到表征空间中(在工程上也常称为嵌入空间,Embedding Space)。在这个框架下,可以直接通过表征之间的几何结构来刻画坍塌。
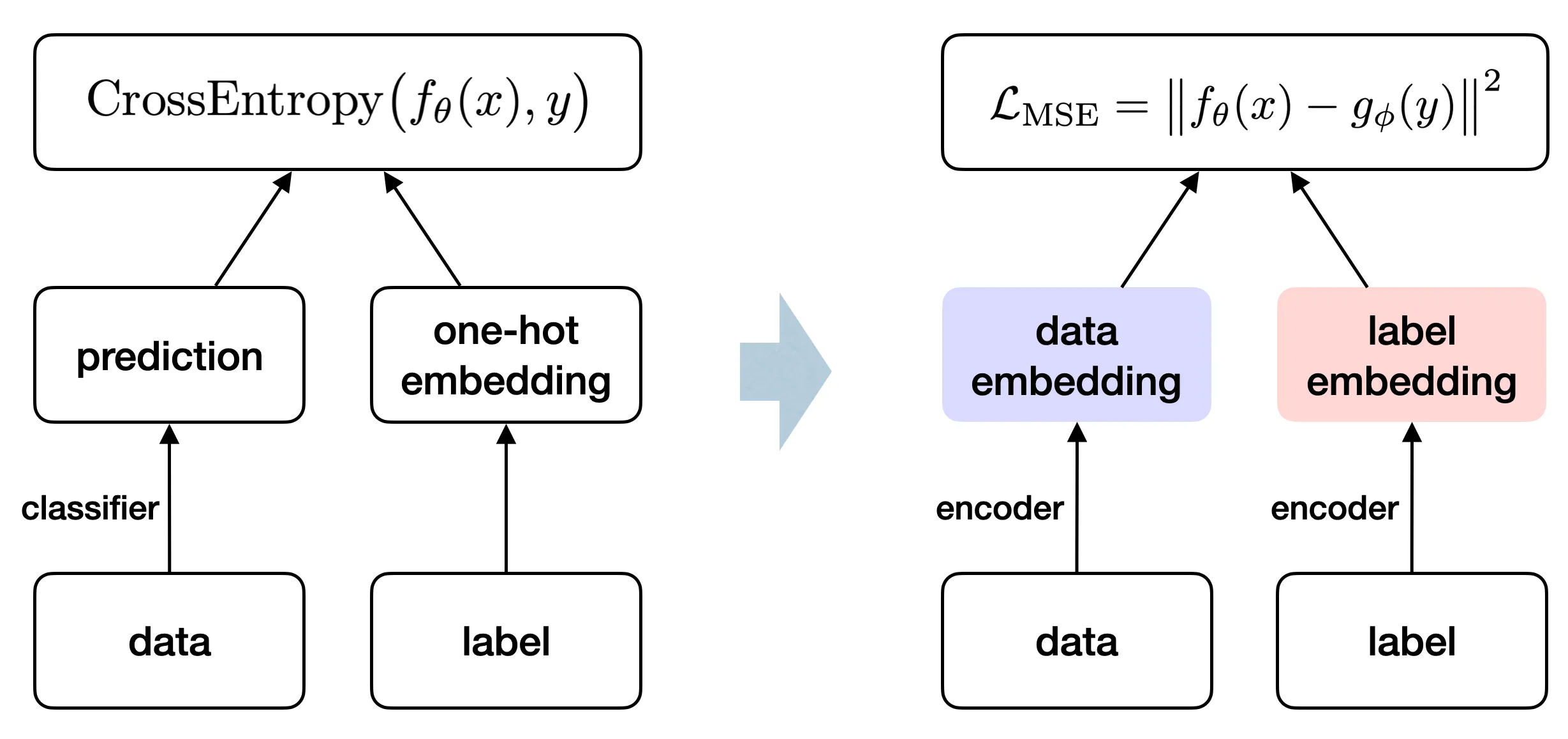
当我们观察分类模型在训练集上的表现时,通常会预期准确率随着训练损失的下降而上升。然而,如果我们同时追踪另一个指标——表征空间中不同类别之间的最小距离
就会发现一个反常的两段式过程。
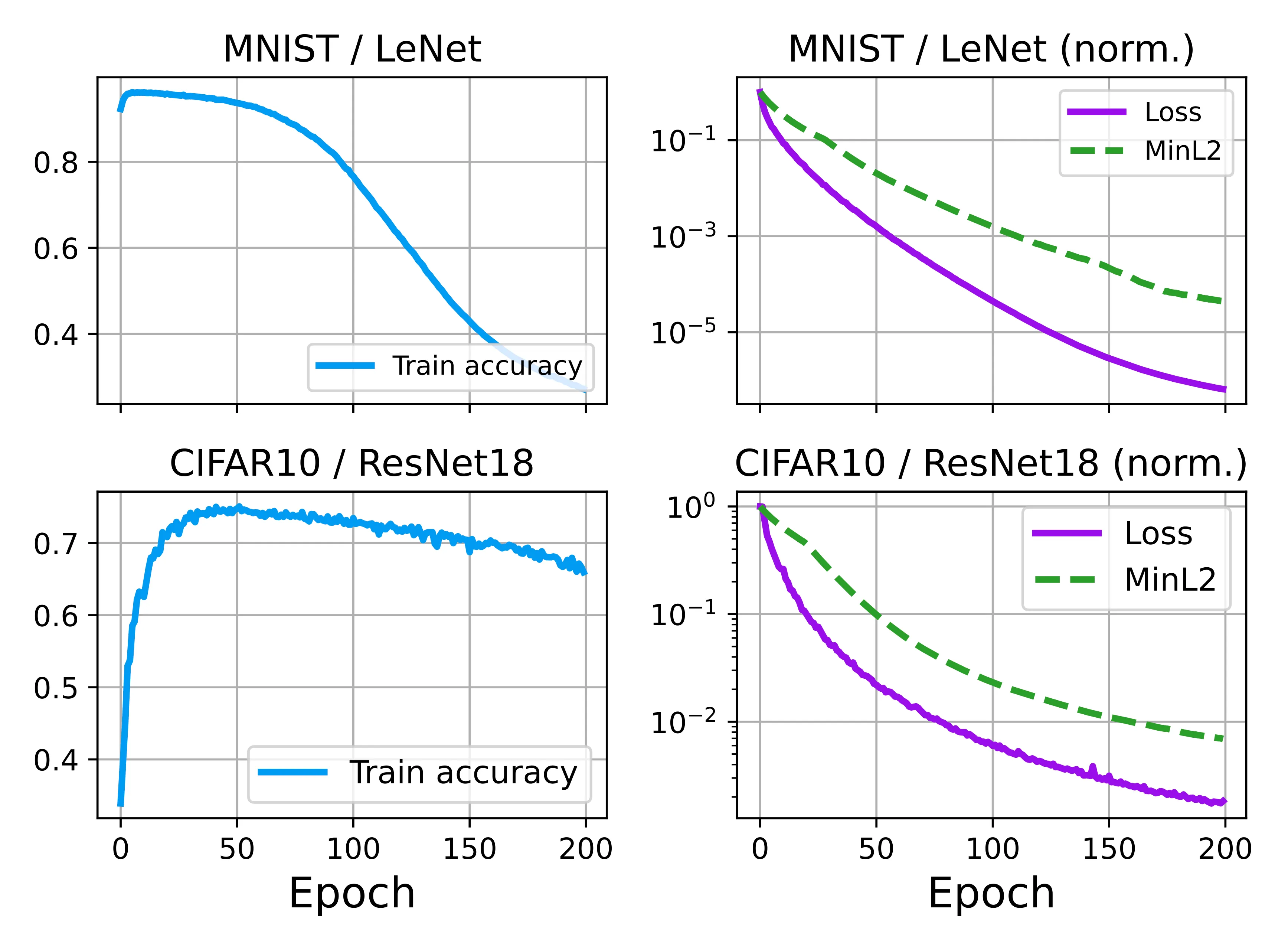
如图所示,在训练初期,准确率迅速上升;但当跨过某个临界点后,即便整体的训练损失仍在下降,准确率却开始衰退。更为关键的是,类间距离(MinL2)在经历了一段初期的缓慢演化后,开始持续且显著地缩小(请注意,右边两图纵坐标为对数坐标)。这意味着,不同类别的表征在训练后期不可逆地滑向彼此,最终导致表征坍塌。
当然,这个现象并不是不可避免的。在实践中,人们发现了一个非常简单却关键的技巧——Stop-Gradient,可以有效地阻止表征坍塌。
从操作上看,Stop-Gradient 会在计算损失时保留前向值,但在反向传播时阻断对应的梯度,使得这一分支不参与模型参数更新。也就是说,模型在“看见”这些表征的同时,并不会试图去改变它们。
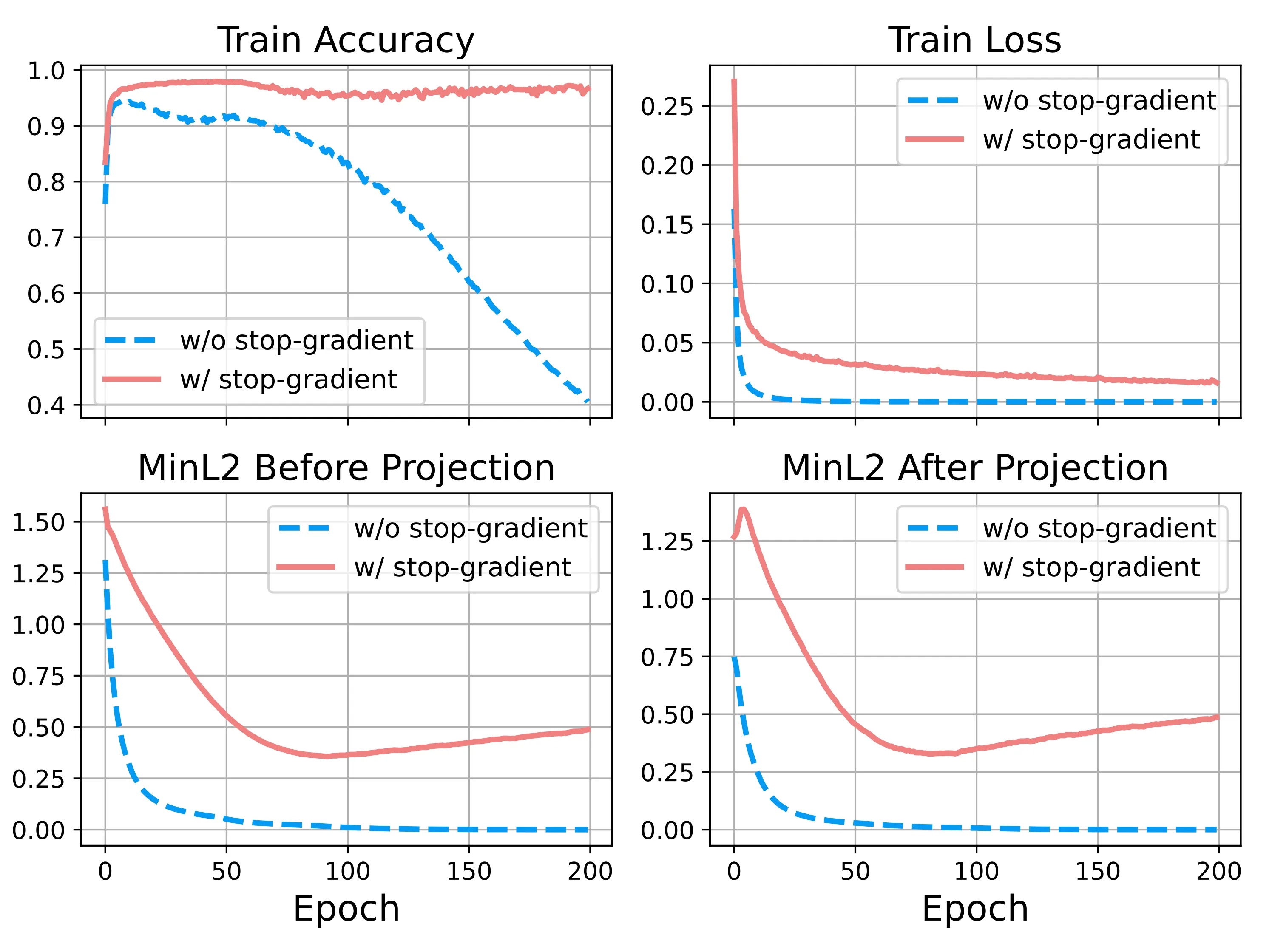
在相同的设定下,我们引入一个共享的投影层(Projection Head),并比较有无 Stop-Gradient 的训练过程。可以看到,训练初期两者几乎没有差别:准确率迅速上升,类间距离也开始演化。但在后期,系统的行为出现了明显分岔。
在没有 Stop-Gradient 的情况下,准确率达到峰值后逐渐下降,同时 MinL2 持续衰减并趋近于零,对应着表征的逐步坍塌;在引入 Stop-Gradient 之后,准确率稳定在较高水平,MinL2 不再继续衰减,而是在一个有限值附近饱和,表明类别之间的几何分离被保留下来。
这说明,表征坍塌并不是必然的训练结果,而是与具体的训练动力学密切相关。看似简单的 Stop-Gradient 机制,足以改变系统的长期演化行为。
物理建模:极简动力学与阻挫
为了刻画上述现象,我们构建了一个极简的梯度流(Gradient Flow)动力学系统。在这一框架中,我们不再显式考虑具体的模型结构 、 和原始数据 ,而是直接将数据样本的表征 和类别标签的表征 视为高维空间中的基本自由度。它们的演化由对齐误差(MSE)驱动:
在理想情况下,如果所有样本都可以被完美地归入各自类别,动力学分析的结果表明:各个类别的表征将独立演化,并最终收敛到彼此分离的稳定构型。由此可见,单纯的对齐优化本身并不会导致表征坍塌。
那么,表征坍塌从何而来?为了解释这一现象,我们引入一个关键概念——阻挫。
在实际的表征学习(尤其是分类任务)中,往往会存在一部分“困难样本”。这些样本或是因为数据本身的噪声、类别之间的本征重叠,或是受到模型表达能力的限制,无法被一致地归入单一类别,而是在表征空间中同时受到多个类别的吸引,对应着一组彼此竞争的对齐约束。
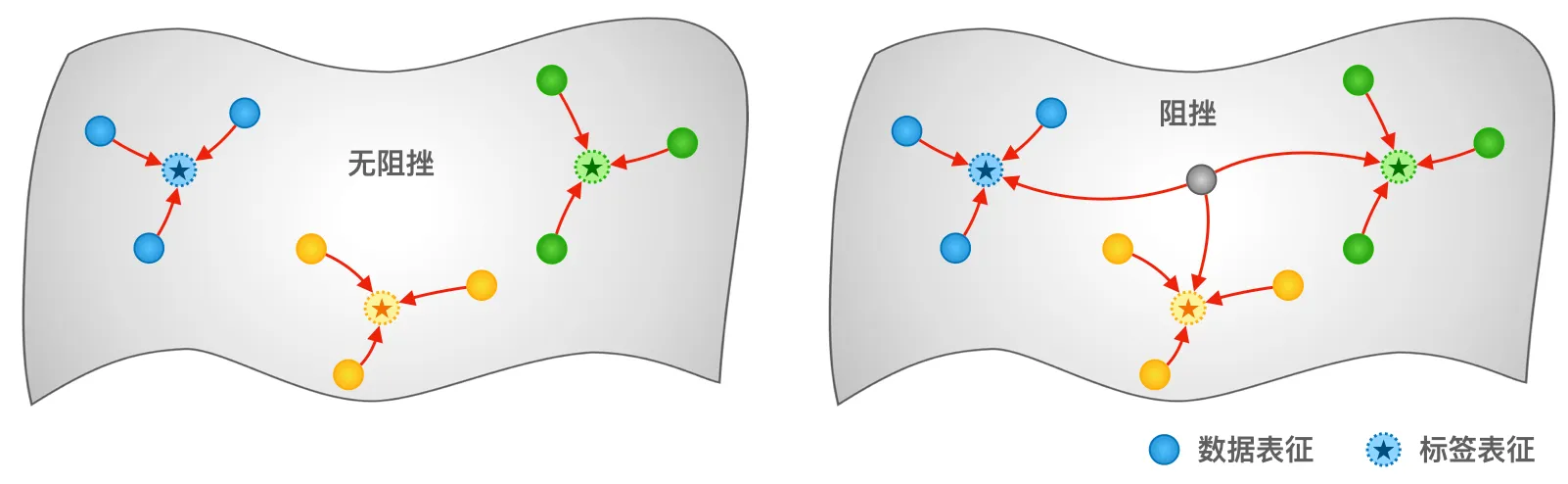
在我们的极简模型中,我们刻意忽略数据与模型的具体细节,直接在表征空间中对这一机制进行建模:设定比例为 的样本为共享样本 ,使其表征同时与所有类别表征进行对齐,从而在动力学中显式引入竞争性约束。这样,损失函数修改为:
从统计物理的视角来看,这正对应于一个典型的阻挫系统:系统中的局部相互作用无法被同时满足,因此不存在能够同时最小化所有局部能量的全局构型。
正是这种内在的不一致性,引入了额外的张力,使系统的演化不再是简单的独立收敛,而是呈现出更加复杂的结构性行为。
动力学分析:不变子空间与时间尺度分离
为了分析系统的演化,我们需要将训练过程(梯度下降)转写成关于表征的动力学方程。在连续时间极限下,表征 和 的变化由损失函数的梯度决定:
对于我们所考虑的 MSE 损失函数,这一动力学具有非常简单的结构:每一个表征都会被“拉向”与其对齐的目标,从而形成一个相互耦合的线性系统。
接下来,我们将在这一框架下分析有无阻挫两种情况各自的动力学演化。
无阻挫情况下的独立演化
首先,我们考察一个完全理想的分类任务,阻挫因子 。此时,每个样本仅与其真实标签的表征产生对齐误差,系统演化方程在不同类别之间是完全解耦的:
对上面的动力学方程进行积分,可以得到一个极其清晰的解析结果:
- 样本层面的收敛:所有的样本表征()会以指数级的速度迅速向其对应的标签表征()靠拢;
- 标签层面的稳定:标签表征自身并非静止不动,但由于只受同类样本的吸引,它最终会渐近地停留在由初始分布决定的某个固定位置。
结论十分明确:在无阻挫的理想状态下,不同类别的表征之间不存在任何相互作用。系统最终会收敛到一个稳定的分类流形上,类别之间将永久保持有限的距离。这从数学上证明了坍塌并非系统的内禀属性。
阻挫诱发的动力学裂解
当我们引入 的阻挫时,这些游离的共享样本打破了类间的独立性,作为相互作用的媒介,使得原本相互独立的类别动力学发生了本质的变化。
为了解析这种耦合系统,我们利用排列对称性,将系统的高维自由度严格分解为三个正交的不变子空间(Invariant Subspace):
- Sector I(样本涨落):描述同类样本内部的离散程度,即 和 。这一子空间中的动力学由对齐项主导,不会引入与阻挫相关的不稳定性,样本依然会在较快时间尺度上向各自类别中心收敛。
- Sector II(类间偏差):各类别表征相对于整体均值的偏离,即 和 。这一子空间刻画了类别之间的相对几何结构,是决定表征是否能够保持分离、或是走向坍塌的核心自由度。
- Sector III(整体平移):描述所有表征质心 的整体移动。这个子空间包含两个随时间衰减的模态和一个零模,只改变整体位置,不影响类别之间的相对关系,因此对表征几何与最终分类性能没有实质影响。
类间偏差(Sector II)的动力学呈现出一个关键结构:其演化矩阵的特征值可以显式写为
在分类问题的典型极限下(单类样本量 ),这两个特征值对应着两个显著不同的演化速率,从而产生明显的时间尺度分离(Time-Scale Separation)。
这个现象可以在数值实验中被直接观察到:
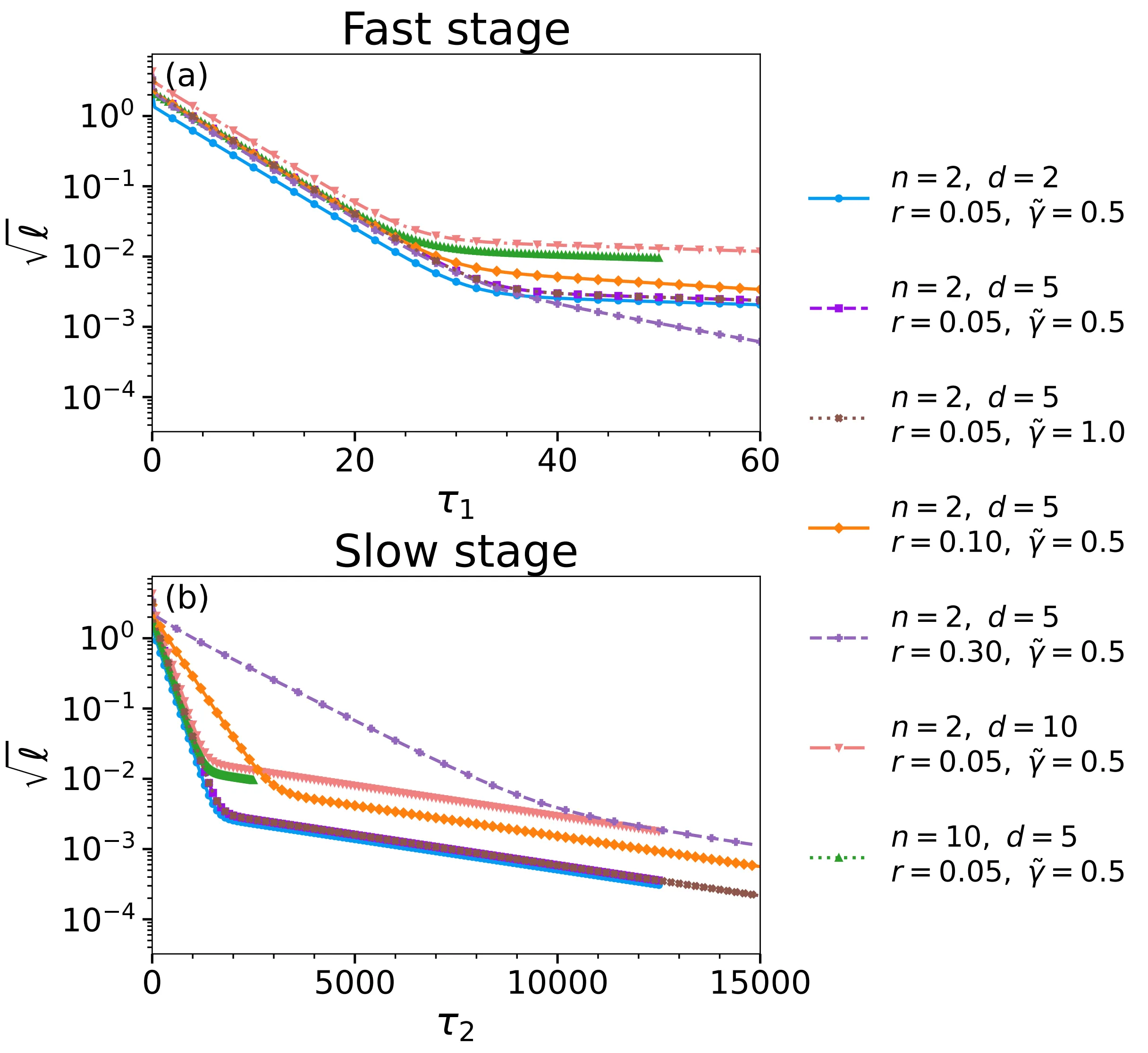
具体而言,一类模式以较快的速率演化,其尺度与系统的尺寸成正比()。这一“快模”主导了绝大多数正常样本与标签之间的对齐过程,使得各个类别在训练初期迅速形成清晰的局部簇结构,对应着我们在实验中观察到的准确率快速上升。
与此同时,还存在另一类由阻挫引入的“慢模”,其演化速率仅由阻挫比例控制()。在初期快速对齐阶段完成之后,系统的长期行为便逐渐被这些慢模所主导。由于共享样本持续施加彼此冲突的对齐约束,这些慢模在不同类别之间引入了一种弱而持久的耦合,使得原本已经分离的类别表征开始缓慢地向彼此靠近。
在这一缓慢演化的驱动下,类别之间的几何分离被逐步侵蚀,表征一点点收缩,最终走向整体坍塌。整个过程并非突发性的崩溃,而是由少量阻挫在长时间尺度上累积放大并逐渐占据主导地位的必然结果。
打破对称性:稳态解析与含时演化
在自监督学习中,以 SimSiam、BYOL 为代表的一系列方法,展现了令人着迷的简洁性:它们不依赖负样本,而是仅通过加入投影层和非对称的 Stop-Gradient 操作,就足以维持表征的区分度。这一方案在工程上大获成功,但其背后的数学逻辑往往隐没在复杂的架构细节中。在我们的极简模型里,我们尝试给出一个关于 Stop-Gradient 为何有效的严格证明。
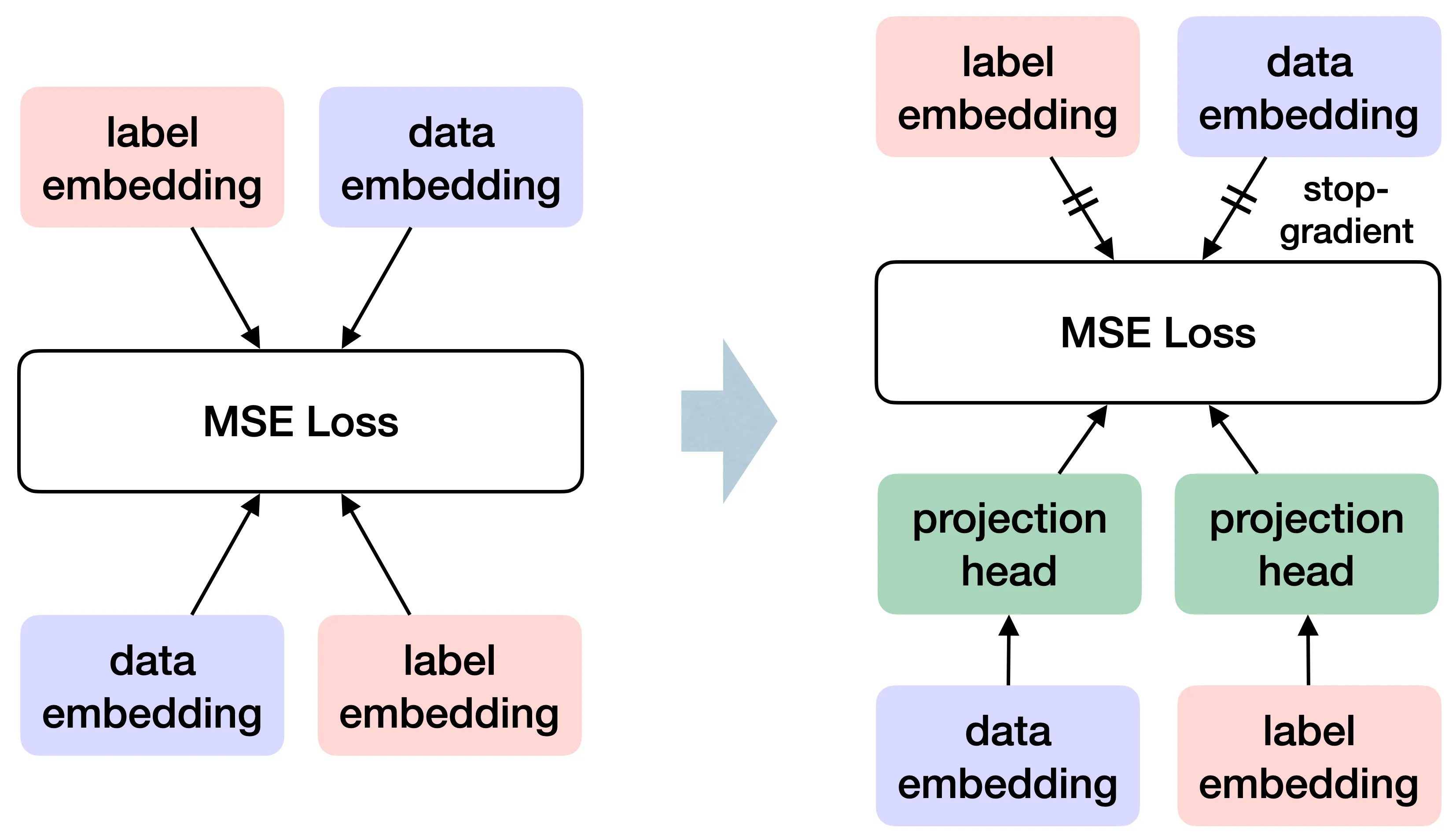
为了分析这一过程,我们在模型中引入一个线性的投影矩阵 。此时,系统的演化不仅取决于表征本身,还受到 状态的调制,构成了一个高度耦合的动力学系统 。
对称梯度反馈下的几何约束
我们首先考察一个关键问题:仅仅增加一个投影头 能否阻止由阻挫诱发的表征坍塌?
没有 Stop-Gradient 的情况下,数据表征与标签表征之间的梯度反馈是完全对称的。这意味着系统的演化依然是一个寻求全局能量最小化的保守力场过程。通过对系统稳态条件(,,)的推演,消去其他变量后,我们可以得到关于类别中心偏差 的一个严格约束方程 :
其中,矩阵 ,算子 由投影矩阵 决定。
显然,为了维持类别间的几何分离,即存在非零的偏差 ,中间的括号项必须存在零空间,这要求算子 必须拥有一个特征值为 。但是对算子 的进一步谱分析可以严格证明,其特征值的模长被始终限制在 之间。
这一矛盾在理论上给出了明确的判据:在对称的梯度反馈下,算子谱的本征结构根本无法满足维持类间距离的拓扑条件 。因此,即使引入了额外的投影自由度,系统最终依然只能给出平凡解 。换言之,在阻挫的引力下,系统必定会滑向唯一的完全坍塌不动点。
非对称动力学中的非坍塌子空间
改变这一演化结局的核心,在于 Stop-Gradient 操作。
从物理学的视角来看,Stop-Gradient 并未修改损失函数定义的能量景观(Energy Landscape),而是改变了由梯度诱导的矢量场。由于 Stop-Gradient 截断了其中一条反馈路径,系统不再沿着能量函数的梯度负方向进行最速下降,从而变成了一个非保守的动力学系统
这种非对称的演化彻底打破了双向耦合带来的几何约束。在稳态条件下,Stop-Gradient 的引入极大地简化了动力学方程,使得我们可以推导出一个关于投影算子 和标签表征 的闭合方程:
这个恒等式揭示了 的特征值谱会自发地分裂为两部分:
- Sector: 在该特征子空间内,方程给出投影关系 ,说明各个类别的表征都被强行映射到了全局均值上,这代表了系统内部强制表征向整体质心收缩的趋势。
- Sector: 这是一个关键的非平凡解空间。分析表明,在该扇区内满足 。这意味着,任何能够区分不同类别的特征分量(即偏差 ),都被严格限制在了特征值为 的方向上。
在 Stop-Gradient 驱动下的动力学,巧妙地在 的特征谱 处产生了一个保护区。系统得以在 sector 内“撑开”一个免受阻挫影响的非坍塌特征子空间。只要表征成分落在这一子空间内,即便系统整体依然受到共享样本的拉扯,这种收缩效应也能被非对称的梯度流所抵消,不同类别之间能够维持有限的几何分离。

通过以上谱分析,我们不仅在理论上证实了 Stop-Gradient 的必要性,更从动力学稳定性的角度,严格证明了它为何能作为一种对称性破缺机制来避免表征坍塌。
DMFT 视角的含时演化
在前面的稳态分析中,我们已经看到了 Stop-Gradient 是如何为系统开辟出非坍塌特征子空间的。但随之而来的自然问题是:系统在漫长的训练过程中,是如何一步步演化到这个稳态的?
当我们在模型中引入可学习的投影矩阵 后,数据表征、标签表征与投影矩阵作为随时间共同演化的动态变量,形成了一个高度非线性的强耦合系统。此时,常规的微分方程组求解方法变得异常困难,难以获得简单的闭合解。
为了刻画这种复杂的含时演化,我们借鉴了统计物理中动力学平均场理论(DMFT)的思想,写出一组 Dyson 型积分方程。在这个物理图景中,我们不再孤立地追踪每一个变量的绝对轨迹,而是将投影算子构成的 Gram 矩阵 视作一个随时间演化的有效介质。表征在介质中演化,而其历史轨迹又反过来影响了投影层,二者形成了一个带有 Dyson 风格记忆效应的自洽闭环。
这套基于 DMFT 风格的积分方程,为理解 Stop-Gradient 非对称动力学的完整含时演化,提供了一个严谨的理论起点。然而,由于有效介质的高度非线性特征,要在解析层面上对这些积分方程进行进一步的降维和精确求解具有极大的挑战性。在本工作中,我们主要确立了这一框架并利用其进行了定性分析。关于如何从这些方程中严格提取出低维的有效动力学,有待未来的工作详细展开。
实证检验:教师-学生模型
在前面的极简模型中,我们将网络结构完全剥离,把表征本身当作可以自由移动的微观自由度。这种处理在数学上极其优美,但也留下了一个悬念:当我们恢复从输入到表征的参数化映射后,由阻挫主导的坍塌机制以及 Stop-Gradient 起到的保护作用,是否依然有效?
为了回答这个问题,我们构建了一个受控的教师-学生模型(Teacher-Student Model)。
我们用一个固定的线性“教师模型”负责生成高维(例如 )的二分类数据与标签。而“学生模型”则是一个简单的单层线性网络,将高维输入映射到低维(如 5 维)的表征空间中。
我们在每个类别中随机抽取比例为 的样本,保持它们的标签不变,但将其在高维特征空间中的位置直接移动到对立类别的特征峰值处。这就人为制造了一批在几何上极具迷惑性、无法被完美区分的样本。在参数化模型中,这种干扰实际上比纯表征模型中的标签模糊具有更强的破坏力,我们可以定义出一个放大的等效阻挫率 。
当我们使用常规的梯度下降训练这个学生网络时,成功复现了动力学中的时间尺度分离:
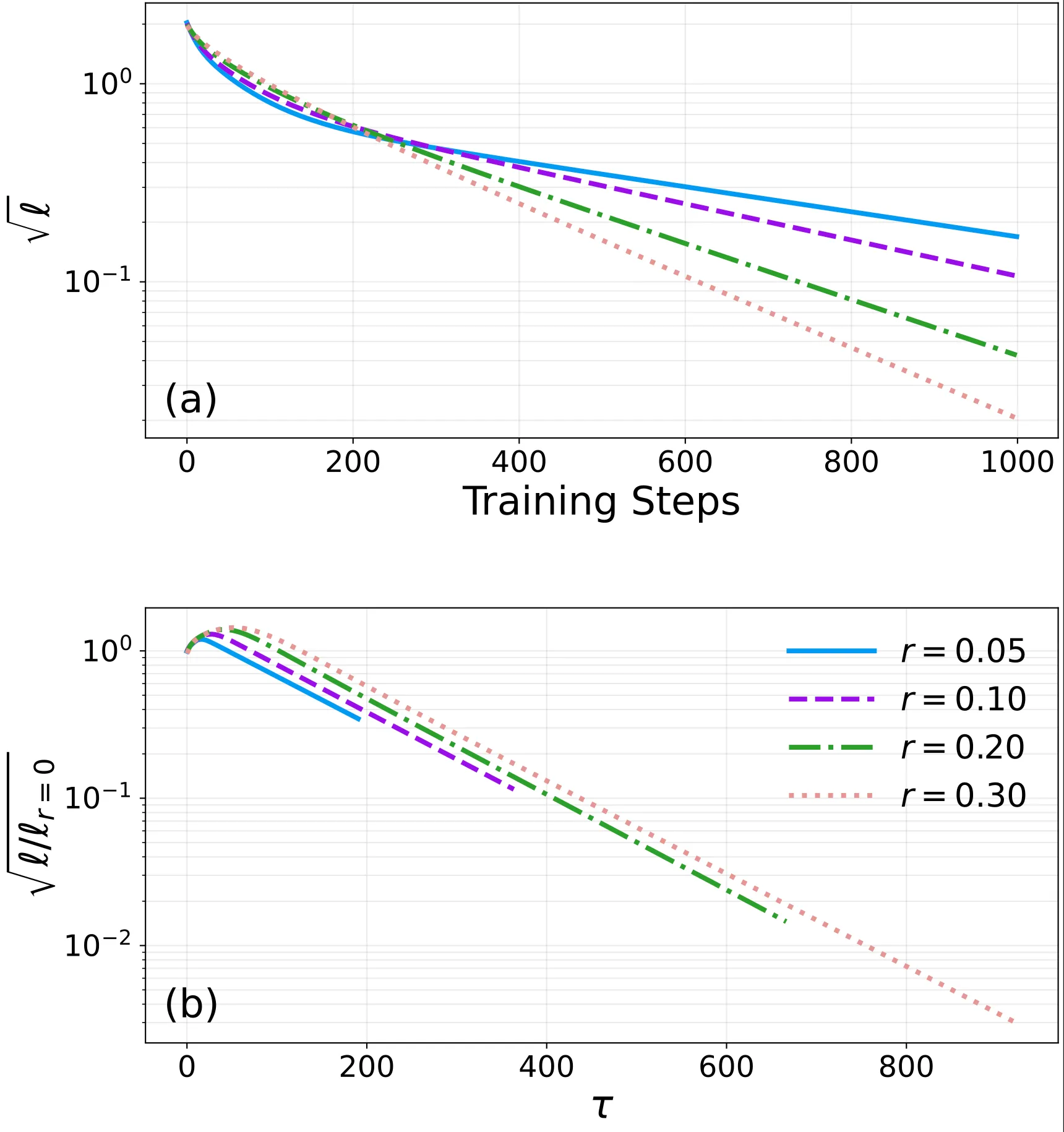
在训练早期,损失快速下降,对应着模型在努力学习那些清晰可辨的正常样本。然而,随着时间推移,演化不可逆转地进入了一个缓慢的衰减阶段。如果我们把时间坐标按照等效阻挫率 进行重新标度(定义有效时间 ),不同阻挫率下的长期衰减曲线在对数坐标下基本平行。
这个结果表明:在真实的含参网络中,主导表征坍塌的时间尺度,依然由系统中的阻挫比例所决定。
最后,我们将投影层和 Stop-Gradient 机制引入这个教师-学生模型。
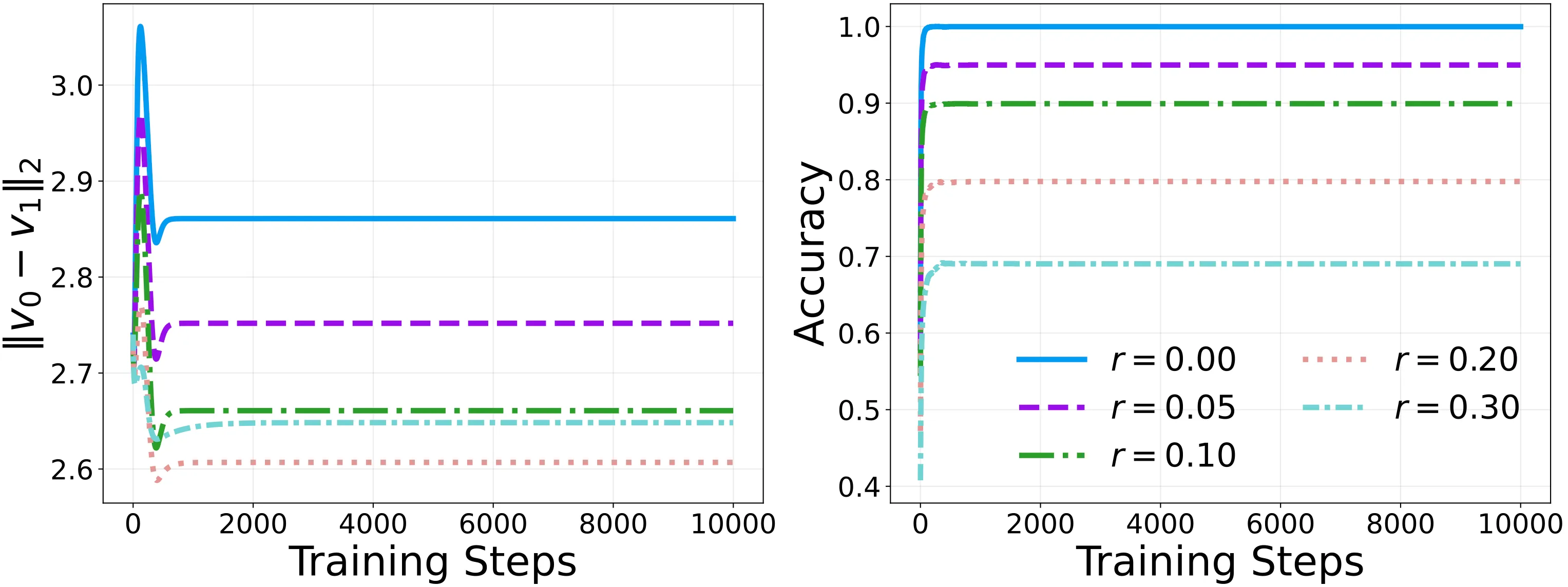
实验结果如理论预期般干净:在阻挫的影响下,类间距离 MinL2 经历短暂的初始调整后,迅速触底反弹并保持平稳,表征免于坍塌。更重要的是,模型的分类准确率也逼近了理想的上限 。
在不加入 Stop-Gradient 时,线性模型天然存在一种尺度等变性,网络可以通过整体缩小参数的绝对尺度来无休止地降低残差,使得类间距离不可避免地滑向零。而 Stop-Gradient 的非对称动力学直接切断了这种纯粹为了降低标度的作弊路径,不仅在几何意义上撑开了非坍塌的特征子空间,更在参数化网络中切实保护了流形空间的宏观区分度。
结语
长期以来,理解现代深度学习框架的核心难点在于:庞大的参数规模与复杂的非线性架构,往往会掩盖系统动力学演化的底层逻辑。在这项工作中,我们采取了一条逆向的路线:不再纠缠于具体的模型微观细节,而是直接从表征空间出发,构建一个干净、简洁的模型。
正如本文研究所揭示的,表征坍塌这种典型的宏观失效模式及其干预机制,其实并不依赖复杂的微观参数配置,而是由少数几个参数和对称性所决定的。这一视角提示我们,现代 AI 模型中许多令人费解的宏观现象并非不可被解析。尝试跳出代码和架构细节的窠臼,就能在更高维度的抽象中,找到直白且深刻的数学解释。
我们希望这种将复杂网络剥离为极简动力学系统的物理视角,能为理解和改进当前 AI 模型的训练机制,提供一些朴素而有力的启发。
如果你认为这项工作对你有所启发或帮助,欢迎引用我们的论文!
@misc{yao2026modelcollapse,
title={A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics},
author={Louie Hong Yao and Yuhao Li and Shengchao Liu},
year={2026},
eprint={2604.09979},
archivePrefix={arXiv},
primaryClass={cond-mat.dis-nn},
url={https://arxiv.org/abs/2604.09979},
}