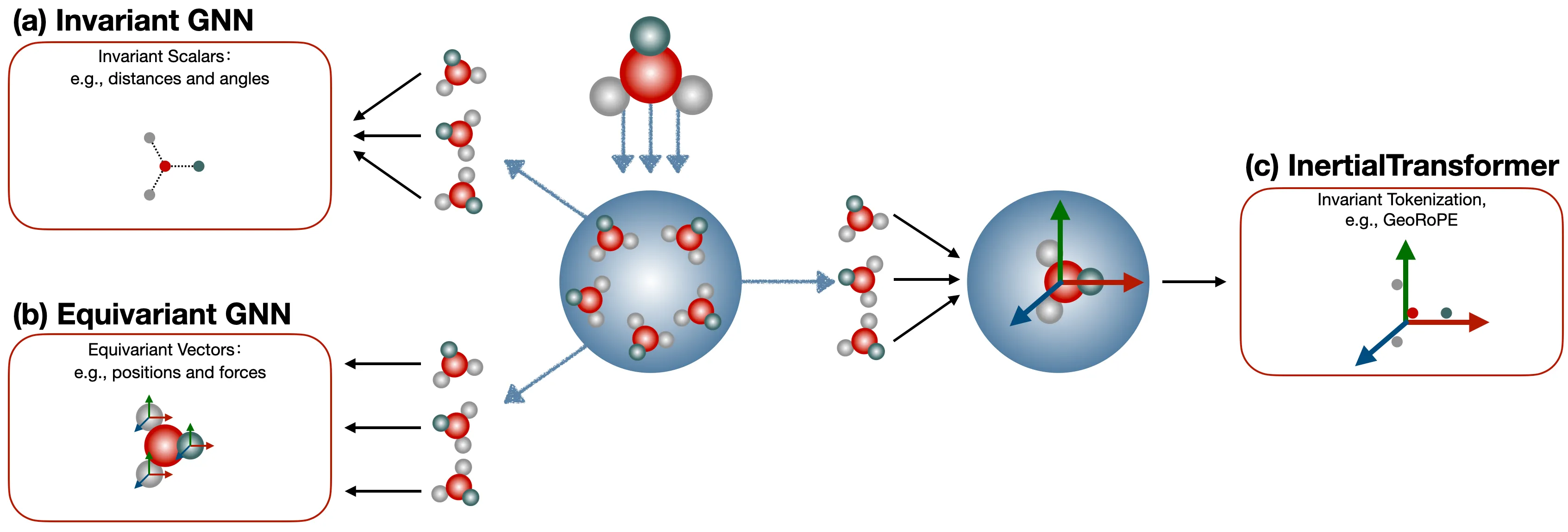
背景:为什么考虑 Autoregressive Model来做3D分子生成?
1) 首先从AlphaFold2和AlphaFold3开始重新思考——物理限制与模型表达能力。 AlphaFold2的核心物理建模是 Invariant Point Attention (IPA)。它利用了 pairwise rigidity frame 的 basis 之间的 inner product 对旋转和平移具有不变性这一特点。(这部分内容如果读者感兴趣我们可以专门开一个专题系列讨论)。这个本质上是一种constrained modeling,牺牲了模型的表达能力,从而得到100%符合SE(3) 等变的特性。而AlphaFold3其实是放弃了完全的对称性特性,而是通过数据增强的方法来尽可能让模型对不同pose的数据进行建模。这就相当于是放弃了完美的等变性,从而释放了模型的表达能力。所以沿着这个方向继续思考,我们是否有可能在同时保证等变性的同时,保持模型的最大表达能力?答案是可以的。我们通过一种数据预处理的方式,比如把小分子根据inertial frame进行矫正(calibration),从而使得所有小分子都使用统一的全局坐标系,即自身的inertial frame。这样本身equivariant的coordinate vector就变成了invariant coordinate vector。剩下的问题就是如何选择一个表达能力强的模型来对invariant vector进行建模。
2) 小孩子才做选择,我们都要——如何让Transformer感知3D结构。 沿着这个方向,很自然的思考就是如何用现在CV、NLP、AIGC领域最expressive的模型,如Transformer,来感知3D分子结构。Transformer主要有三个模块,token embedding、positional encoding和self-attention。这里我们很自然的选择是设计Transformer的positional encoding,从而使得它能够感知3D结构(具体有很多有意思的原因,我们准备放到第二弹继续探讨)。那在具体做法上,我们受到Jianlin Su的RoPE影响有一些思考;如果只是单纯把RoPE放到一个3-channel的coordinate空间上,那其实是在计算L1 norm,或者Manhattan distance。这里我们引入了Nyström estimation来计算L2 norm,也就是Euclidean distance。
3) 从GenAI角度的最大难点——连续与离散数据的同时生成。 这个是很多科学类问题独特的问题,比如在经典体系下,小分子的原子类型是离散变量,而坐标是连续变量。如何把它们很好地同时生成是一件non-trivial的事情。目前,3D分子领域,主流的生成范式是扩散模型 (Diffusion Model),比如EDM等,它们在连续变量(坐标)上表现优秀,但本质上是为连续空间设计的,处理离散变量(原子类型)时需要额外trick。更关键的是,扩散模型依赖多步迭代去噪,采样慢、且天然不擅长处理变长序列。此外,现有的3D分子扩散模型通常依赖SE(3)等变的图神经网络作为backbone,这类专用架构与文本、图像等模态主流的Transformer范式存在天然的架构壁垒,难以直接融入多模态基础模型的统一框架。而自回归模型 (AR) 恰好提供了一个互补的视角。AR模型的核心范式 Next Token Prediction天然支持变长生成和高效解码。但经典的AR模型(如GPT)只处理离散token(词表中选一个词),不能直接回归连续坐标。如果强行将坐标离散化(Discretization),会丢失精度;如果强行用L2 loss直接回归坐标,我们的实验表明模型会collapse。InertialAR的解法是一种很自然的分层策略:先预测”下一个原子是谁”(离散分类),然后再用Diffusion Loss预测”它具体在哪”(连续去噪),使得AR模型的序列生成能力与Diffusion的连续建模能力被优雅地”嵌套”在一起。
SE(3)不变性保证、几何感知的位置编码、离散-连续联合自回归生成,构成了InertialAR的三块核心拼图,也对应了论文的三个主要方法模块。下面我们逐一展开。
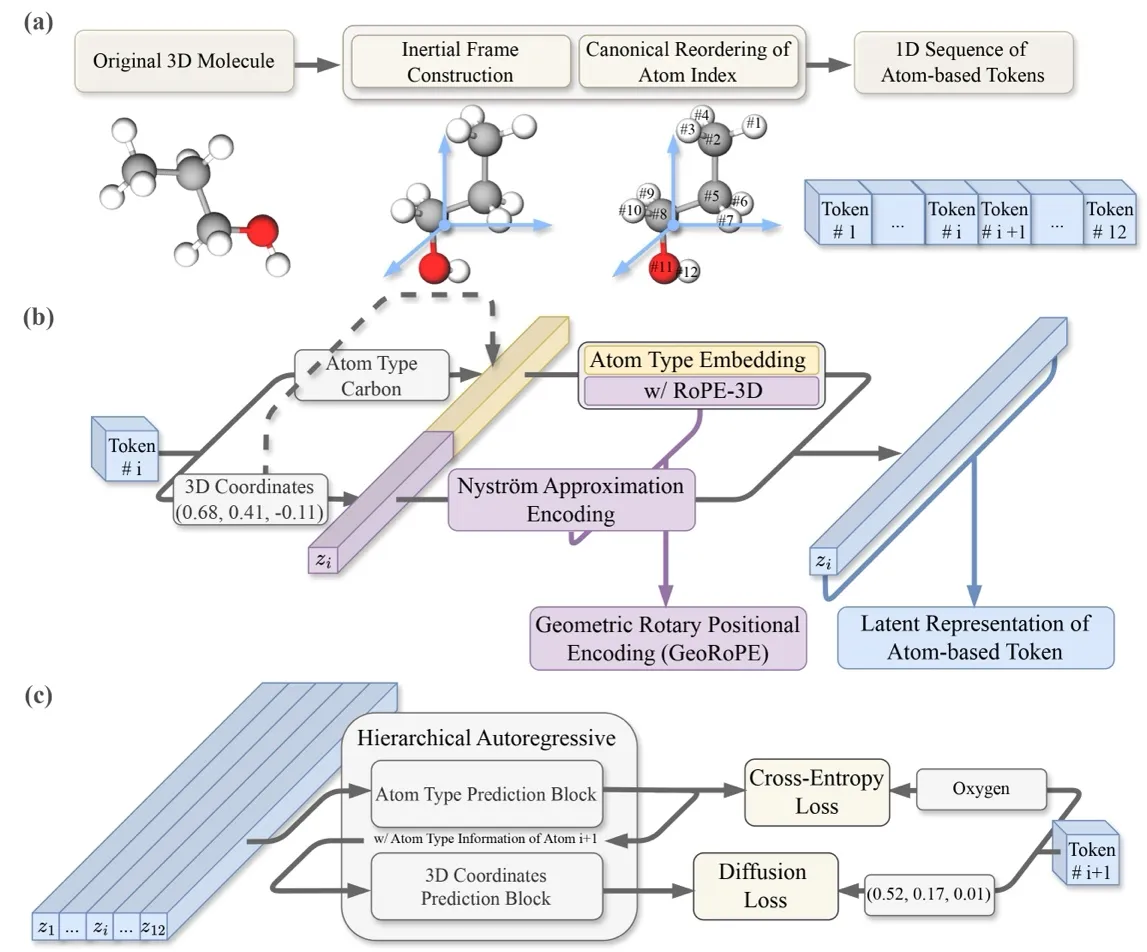
拆解InertialAR:摆正分子、看懂几何、逐原子生成
把分子变成唯一的序列:Generation-oriented Canonical Tokenization
要做自回归生成,第一步就是把3D分子变成一条1D序列。思路很直接:把每个原子当作一个token: ,其中 是原子类型, 是3D坐标,然后按某种顺序排列起来,就能像语言模型一样逐个预测:。
但这里有一个关键问题:同一个分子,旋转一下、平移一下,坐标就全变了;原子的编号换一种顺序,序列也完全不同。如果这些”本质相同”的分子在训练时被当成不同的样本,模型就没法学到一致的分布。所以,我们需要保证SE(3)的不变性和原子排列的不变性。
把分子”摆正”——对齐到Canonical Inertial Frame: 以前的模型为了搞定SE(3)不变性,往往要在网络结构里设计复杂的等变层,像是戴着镣铐跳舞,限制了模型发挥。而我们选择通过数据预处理来保证SE(3)不变性,具体方法借用了物理里的”惯性参考系”的概念:每个刚体都有自身的主惯性轴 (principal axes of inertia)。InertialAR先将分子平移到质心,再对惯性张量做特征值分解,得到三个正交的主惯性轴作为坐标系。不过,三个正交轴仍存在±1的方向歧义(共4种可能的右手坐标系),InertialAR通过选取一个最远端的”锚点”原子来唯一确定轴的正方向。这样,无论分子原来在空间中怎么摆放,经过这套流程后都会被”摆正”到同一个规范姿态。
给原子”排队”——规范化原子排序: 即便分子姿态固定了,一个分子由n个原子组成,这n个原子仍有n!种排列方式。InertialAR利用RDKit的canonical SMILES规则,根据原子的化学性质(原子序数、连接度、环成员等)进行确定性排序,把n!种排列归约为唯一序列。
到这里,每个分子就对应了唯一的一条token序列,可以交给自回归模型了。但序列有了,Transformer怎么知道这些原子token之间的3D空间关系呢?这就引出了下一个问题。
让Transformer”看懂”3D几何:GeoRoPE
标准Transformer只认识序列位置(第1个token、第2个token),对3D空间中的远近关系一无所知——第i个和第j个token在注意力里相互关注,并不意味着对应的两个原子在空间上就更近或更相关。要让Transformer真正”看懂”分子几何,我们选择从positional encoding入手注入空间信息。具体怎么做?
一个很自然的起点是RoPE (Rotary Position Encoding)。Jianlin Su提出的RoPE之所以好用,是因为它有一个优美的数学性质:变换后Query和Key的内积仅依赖于相对位置,而不受绝对位置影响。InertialAR把这个思想从1D序列扩展到3D坐标空间——让Attention依赖的是原子间的相对位置向量 ,即 。
但正如背景中指出的,单纯把RoPE放到3D坐标上,本质上是沿x、y、z三个轴独立编码,捕捉的更接近L1 norm(Manhattan distance),而不是我们真正想要的L2 norm(欧氏距离)。怎么补上这块?InertialAR引入了Nyström方法:通过固定的锚点对基于欧氏距离的 RBF 核矩阵做低秩近似,并构造特征向量 ,使得 ,从而将成对距离信息以”向量点积”的形式注入Attention。这样,最终的Attention Score形式变成了:
因此实现了,前一项捕捉相对位置,后一项捕捉成对距离,两者”并联”互补的功能。
这里有一个容易被忽略但很关键的工程设计:为什么不直接把距离信息作为bias加到注意力矩阵上?因为那样做会改变标准的Attention实现,破坏与当前主流LLM架构的兼容性。Nyström编码的精髓在于,它把成对距离计算转化成了向量点积,几何信息因此可以像普通token特征一样被处理,完美复用标准的矩阵乘法注意力。这也是InertialAR能够scale up的关键。
让AR模型同时预测”是谁”和”在哪”:Hierarchical AR with Diffusion Loss
序列问题和几何感知问题都解决了,最后一个问题回到我们在背景第三点的讨论:AR模型天然擅长离散分类(选一个词),但不能直接回归连续坐标。如果强行用L2 loss预测坐标,模型会直接collapse。那怎么办?
InertialAR的做法是把每一步的”预测下一个原子”拆成两个级联的子任务。先用Cross-Entropy预测原子类型(“下一个是碳还是氧?”),再用Diffusion Loss预测它的3D坐标(“它具体在哪里?”)。数学上就是条件概率的自然分解:
Diffusion Loss vs. L2 Loss: 相较于硬着头皮去回归一个绝对精确的坐标值,Diffusion Loss教模型学会”去噪”,教模型如何从噪声中一步步”洗”出结构。消融实验也证实,在自回归框架下,用 Diffusion 去建模连续分布,才是生成高质量 3D 结构的必经之路,这也与Kaiming的MAR的发现一致。
可控生成:把Classifier-Free Guidance同时用到两条支路
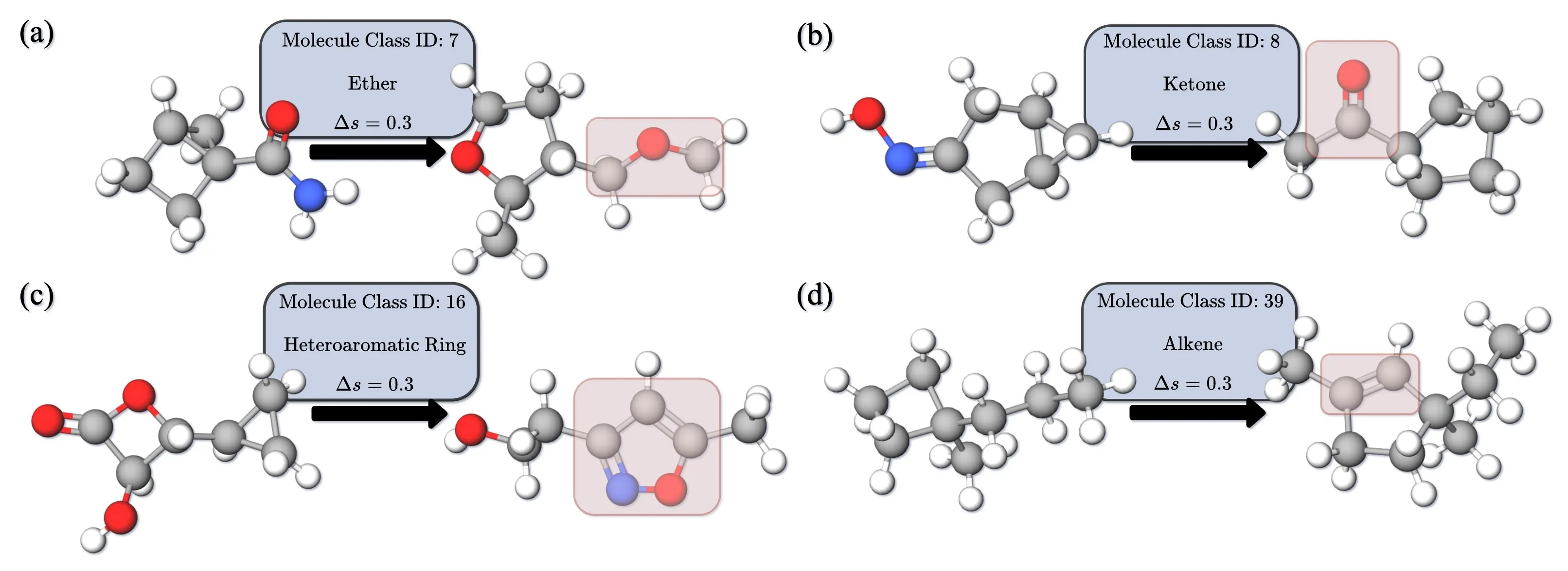
InertialAR还支持按功能基团类别定向生成分子。具体做法是引入Classifier-Free Guidance (CFG):训练时随机丢弃部分类别标签,让模型同时学到条件分布和无条件分布;推理时通过guidance scale来调控条件强度。
这里有一个有意思的设计选择:很多可控生成方法只在连续分支(坐标去噪)上做guidance,但InertialAR同时在类型预测的logits上也做了guidance。道理很简单——如果你只引导坐标而不引导原子类型选择,生成出的原子类型序列可能本身就和目标类别不匹配,再怎么调坐标也没用。两条支路都加上CFG,才能同时保证”化学合理性”和”条件符合度”。
论文还展示了一个有趣的延伸应用:通过逐步提高guidance scale,可以将一个不合理的分子逐步”编辑”成满足目标类别的合理结构——类似图像领域的guided editing。
实验结果
无条件生成
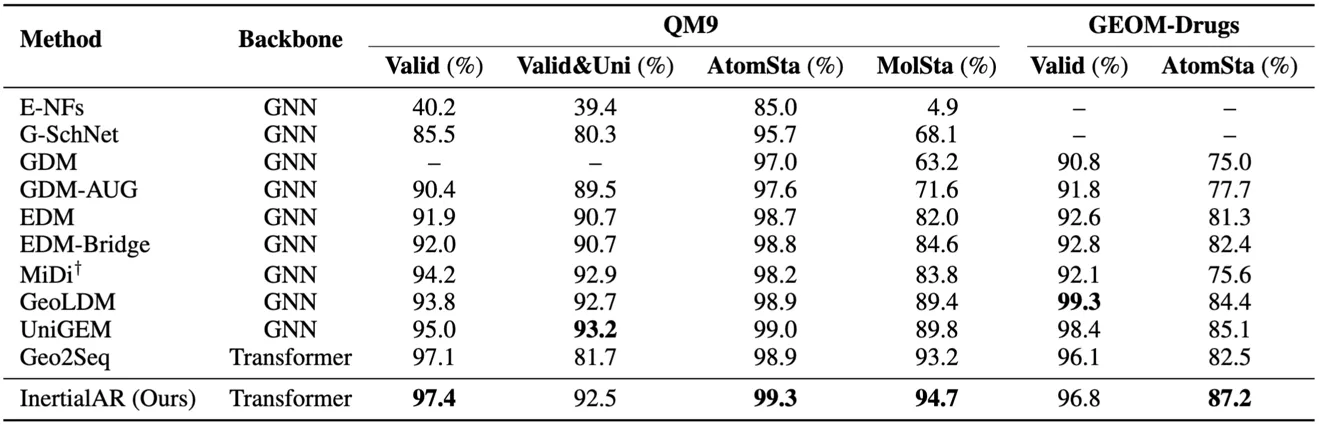
- QM9: InertialAR 在 Valid (97.4%)、AtomSta (99.3%) 和 MolSta (94.7%) 三项指标上达到最优,超越所有扩散模型和AR baseline。
- GEOM-Drugs: 在更大规模和更复杂的药物分子数据集上,InertialAR 的 AtomSta (87.2%) 为所有方法中最高,Valid (96.8%) 仅次于 GeoLDM (99.3%)。
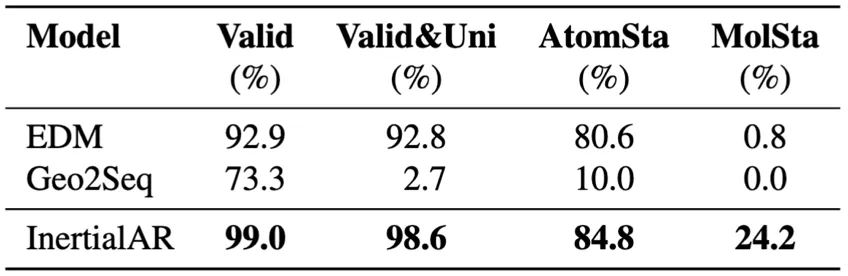
- B3LYP-1M(百万级数据): InertialAR 以 Valid 99.0%、Valid&Uni 98.6%、MolSta 24.2% 在全部4项指标上取得最优。这一结果有力证明了InertialAR的scaling能力——在数据量增大、化学多样性增加的场景下,InertialAR不仅没有退化,反而展现出更强的优势。
可控生成(QM9, Class-conditional)
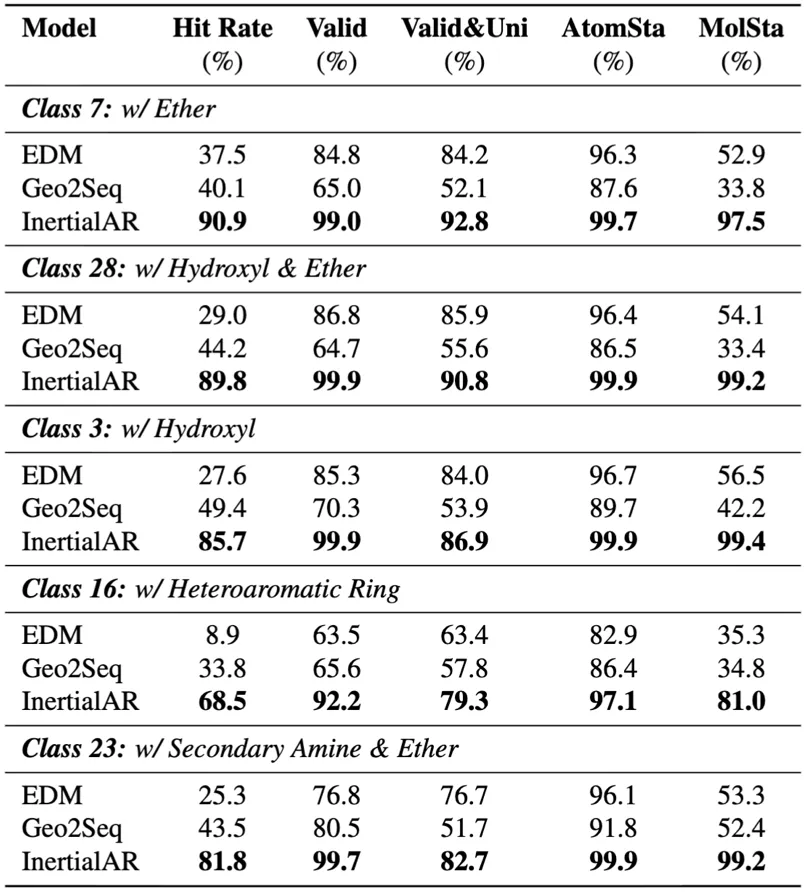
InertialAR在全部5个评估指标上达到SOTA,平均Hit Rate 83.3%,显著超越baseline。同时,在Classifier-Free Guidance的加持下,InertialAR在保持分子化学合理性的同时,精准地满足了设计要求。
总结与展望
InertialAR通过三个核心模块——面向生成的规范化序列(Generation-oriented Canonical Tokenization)、几何感知的注意力机制(GeoRoPE)以及层级式自回归解码(Hierarchical AR Paradigm)——成功将 Transformer 的序列建模能力引入了 3D 分子生成领域。综合无条件和可控生成任务,InertialAR在10个无条件生成指标中拿到8个SOTA、5个可控生成指标全部SOTA。
回到我们在背景部分提出的三个问题,InertialAR给出了一套完整的回答:
- 物理限制 vs. 表达能力? 通过输入规范化(inertial frame)保证SE(3)不变性,同时解放模型表达能力;
- 如何让Transformer感知3D? 通过GeoRoPE将相对位置和欧氏距离注入注意力;
- 离散与连续如何同时生成? 通过分层AR + Diffusion Loss实现级联解码。
这项工作的意义不止于一个表现更好的生成模型,它更指向了两个值得期待的方向:
-
向更复杂的科学体系拓展。 InertialAR的”规范化 → 序列化 → 自回归生成”范式并不局限于小分子。蛋白质结构建模、周期性材料设计等场景同样面临 SE(3) 对称性和变长结构的挑战,这套方法论有天然的迁移潜力。
-
与其他模态的统一建模。 既然3D分子结构可以被规范化为一维token序列,它就具备了与文本、图像等模态在同一个Transformer框架下联合建模的基础条件——这正是构建科学领域多模态基础模型所需要的关键一步。
Cite Us:
@misc{li2025inertialarautoregressive3dmolecule,
title={InertialAR: Autoregressive 3D Molecule Generation with Inertial Frames},
author={Haorui Li and Weitao Du and Yuqiang Li and Hongyu Guo and Shengchao Liu},
year={2025},
eprint={2510.27497},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.27497},
}