(★ This Blog is a work by Tianyue Yang. See his homepage and the original blog K-Flow - The Physical Origin ★)
Flow Matching: A Physicist’s Perspective
One of the earliest and most influential scientific observations of randomness in nature came from Brownian motion: the irregular movement of pollen particles suspended in water. This phenomenon offered a visible manifestation of microscopic fluctuations and later helped inspire the microscopic theory of gases, in which the macroscopic behaviour of matter is explained through the random motion of an enormous number of particles. Diffusion, a fundamental transport process that appears throughout the physical world, was subsequently studied and formalised by physicists and mathematicians. Their work established the mathematical foundations for describing how particles, energy, or probability distributions spread over time. These ideas later became central to modern transport theory and now provide an important theoretical basis for diffusion-based methods in machine learning, including diffusion models for generative modelling.
Flow matching, one of the state-of-the-art frameworks in generative modelling, also admits a natural interpretation from physics. Its mathematical structure is closely related to transport dynamics in classical mechanics, especially the way probability densities evolve under a prescribed velocity field. This connection makes flow matching not only a powerful machine learning method, but also a conceptually appealing one, since it can be illustrated through well-established physical principles. The dynamics of flow matching are typically defined by the ordinary differential equation
where is a time-dependent velocity field that transports samples through the data space. Rather than modelling randomness explicitly, this formulation describes deterministic motion along trajectories induced by .
The probability density transported by this flow evolves according to the continuity equation
where denotes the marginal density at time . This is simply the statement of conservation of probability mass: as particles move under the velocity field , the total probability is preserved, even though the density may locally expand or contract. Following the density along a characteristic trajectory , we obtain
This relation shows that the divergence of the velocity field directly controls how the density changes along the flow. When , the flow locally expands and the density decreases; when , the flow contracts and the density increases. From this perspective, flow matching can be viewed as learning a transport process that continuously reshapes one probability distribution into another. This transport picture is deeply familiar in physics. Variants of the same continuity structure appear in electrodynamics, fluid mechanics, and quantum mechanics whenever one tracks the evolution of a conserved quantity. A particularly clean example is Hamiltonian mechanics, where the dynamics in phase space are generated by a symplectic vector field. In that case, the flow is volume-preserving, so the divergence vanishes:
Hamilton’s equations are
where and denote position and momentum, respectively. In Hamiltonian mechanics, the motion of a system is represented as a trajectory in phase space, with coordinates . We then introduce a phase-space density describing an ensemble of systems. By conservation of the number of systems in the ensemble, the density satisfies the continuity equation
where the phase-space velocity is
The divergence of this velocity field is
Thus, Hamiltonian flow preserves phase-space volume, which is the usual statement of Liouville’s theorem in classical mechanics. Equivalently, the density remains constant along trajectories:
This gives a useful physical perspective on flow matching. Like Hamiltonian transport, flow matching describes the evolution of a density under a velocity field. The key difference is that flow matching does not require phase-space volume to be preserved. Its learned vector field may expand or contract probability mass locally in order to transform one distribution into another. In this sense, flow matching can be understood as a generalised transport process: it retains the continuity-based structure familiar from physics while relaxing the strict incompressibility that characterises Hamiltonian dynamics.
When Scaling Evolves: From Renormalisation Group to K-Flow
In traditional flow matching, the introduction of the time parameter can feel somewhat artificial. Since the flow is not generally volume-preserving, the notion of time does not arise as naturally from the physical picture discussed above. This motivates a different question: instead of tracking how a system evolves in time, can we describe how it evolves across scales? In condensed matter physics and quantum field theory, this question leads to the renormalisation group (RG). The central idea is that many physical systems exhibit self-similar structure across different length or energy scales, and one therefore seeks a framework that describes how the parameters of an effective theory change as the observation scale varies.
In RG theory, the evolution of a coupling parameter with respect to the effective energy scale is governed by the renormalisation group equation
where is the beta function, encoding how the effective theory changes with scale. Rather than describing motion in time, this equation describes motion in scale space.
This perspective suggests a natural reinterpretation of generative flow: instead of evolving along an abstract time variable, one may evolve along a physically meaningful scale parameter. A useful intuition comes from the fact that, in many physical systems, energy-like quantities are associated with squared frequency or squared wave number. In quantum mechanics, for example, one often encounters relations of the form
For natural images and other structured signals, analogous scale information can be extracted through K-transforms, such as Fourier or wavelet transforms. If denotes the coefficient at scale , then it is natural to associate an effective scale-dependent energy with its amplitude:
This provides a physically motivated way to organise information by scale, rather than by an externally imposed time coordinate. Under this viewpoint, the governing equation of K-Flow can be written as
where denotes the observable evolving along the scale parameter , and is the corresponding scale-dependent velocity field.
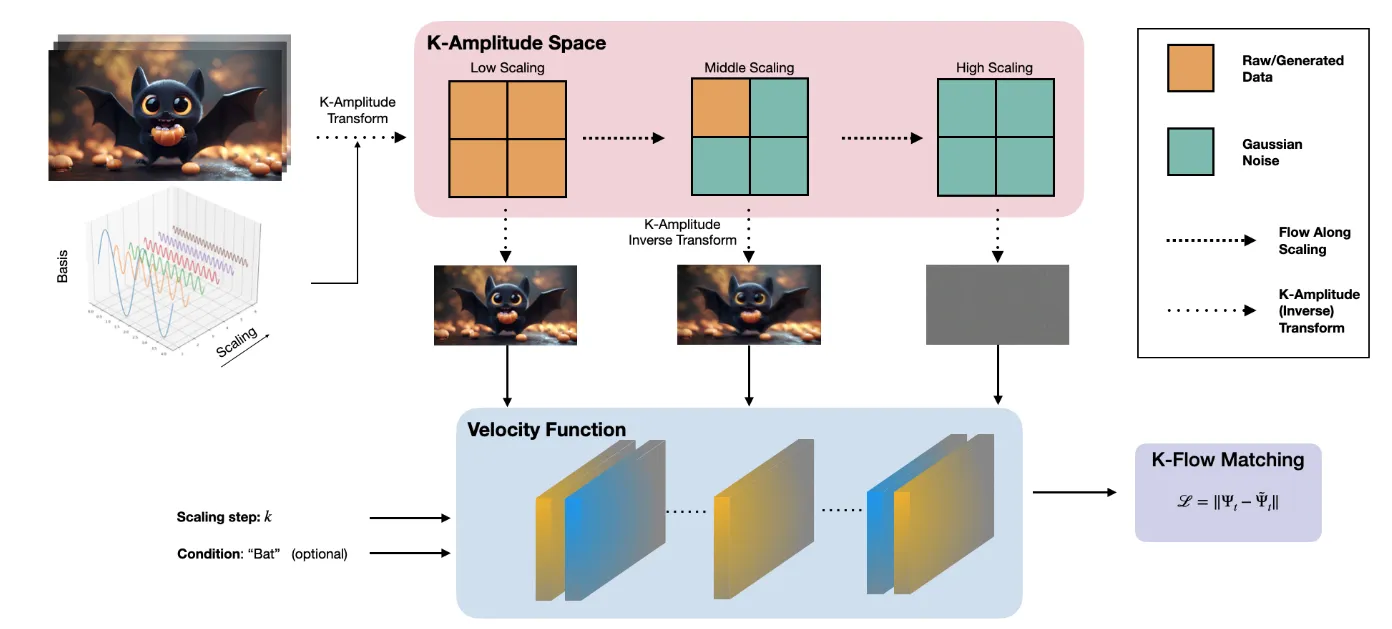
More concretely, is constructed by progressively revealing transform coefficients up to scale , while the remaining components are padded or interpolated with noise:
where is the indicator function, denotes the chosen K-transform, is noise, and parameterised the interpolation within a single scale shell. This construction suggests a close analogy with RG:
In both cases, the central object evolves not in physical time, but along a scale parameter that organises the degrees of freedom of the system. From this perspective, K-Flow can be interpreted as a scale-wise transport process, in which information is generated or reconstructed progressively across frequency bands. The analogy is not exact in a strict field-theoretic sense, but it is conceptually useful: RG describes how effective descriptions change with scale, while K-Flow describes how observables are transported across a hierarchy of scales in transform space.
This scale-wise structure also leads to a localised probabilistic interpretation. By the telescoping decomposition of conditional probabilities,
the marginal distribution at step is effectively localised around the current scale shell. In other words, only a restricted band of coefficients is actively being updated, while lower-scale components are already determined and higher-scale components remain noise-dominated.

This resembles the notion of shell localisation in renormalisation group theory, where one studies how the effective description changes as degrees of freedom are integrated in or out shell by shell. Seen in this way, K-Flow replaces the abstract time variable of conventional flow matching with a more structured and physically interpretable evolution across scales.
Performance of K-Flow
In the K-Flow paper, we conducted extensive experiments across a variety of datasets, including both class-conditional settings, such as ImageNet-256 with a VAE, and unconditional settings, such as CelebA-HQ.
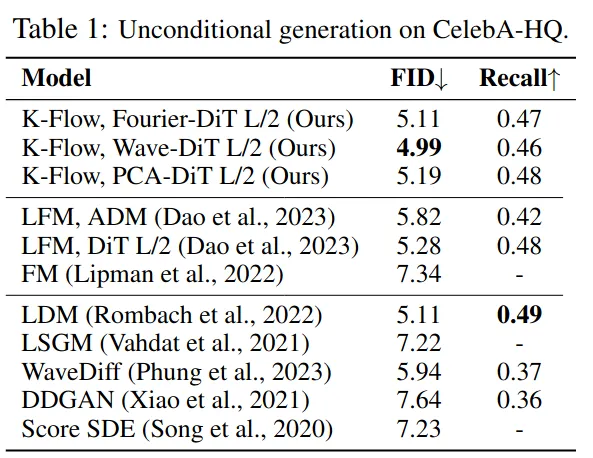
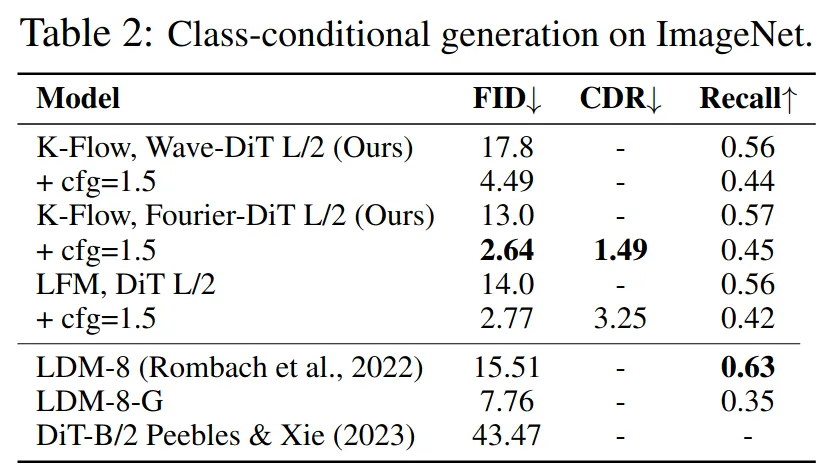
Across these benchmarks, K-Flow achieved competitive results, as summarised in Tables 1 and 2. More intriguingly, we observed a striking phenomenon: class-conditional labels can be removed at a very early stage of generation without noticeably degrading sample quality, as illustrated by the samples below.

This provides strong experimental evidence that our energy-driven approach is learning an internal representation that aligns closely with the natural image manifold, rather than relying solely on label information throughout the entire generation process.
Conclusion and Outlook
Although our framework is not only theoretically inspiring but also practically effective, the current approach remains significantly constrained by the VAE-induced latent space. This limitation prevents the model from learning an explicit representation directly in pixel space. From both theoretical and applied perspectives, several promising directions remain open:
-
Extending K-Flow beyond latent-space generation.
Can K-Flow be trained directly in pixel space using more efficient architectural designs? More broadly, can the K-Flow formulation be adapted to parameter-efficient fine-tuning (PEFT) settings, allowing it to improve the efficiency of existing pre-trained models? -
Applying K-Flow to scientific generation tasks.
Can the K-Flow framework be used in scientific domains where there exists a genuinely interpretable energy functional? Such settings may offer an opportunity to test the theoretical foundations of K-Flow more directly and rigorously.
We believe these questions open up exciting opportunities for future work.
Please consider citing our paper if you found this work interesting or useful!
@inproceedings{du2026flow,
title={Flow Along the \$K\$-Amplitude for Generative Modeling},
author={Weitao Du and Jiasheng Tang and Shuning Chang and Yu Rong and Fan Wang and Shengchao Liu},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={<https://openreview.net/forum?id=O224NIizhz>}
}