This blog post introduces one of our works in 2024, K-Flow - Flow Along the K-Amplitude for Generative Modeling.
In the past two years, when discussing “multi-scale” generative models, it has been easy to think of some naive concepts: “low frequencies are responsible for contours, high frequencies for textures,” or “generate the shape first, then fill in the details,” like the process a human painter uses when creating artwork. This intuition is correct, but our K-Flow is beyond a simple “frequency-aware multi-scale flow matching model.”
The true novelty of K-Flow is not merely projecting data into spaces such as Fourier, Wavelet, or PCA to observe different frequency bands, but rather proposing a more fundamental generative perspective. It uses the scale parameter to organize different bands, constructs the physical quantity “amplitude” to describe the coefficient norm on these bands, and finally allows the generation process to flow along this K-amplitude axis (different from the time variable in traditional diffusion and flow matching).

TL;DR:
K-Flow is based on the K-amplitude transform and features six core characteristics:
- Scaling-aware flow interpolation.
- Multi-scale modeling in the K-amplitude space.
- Energy-aware scaling.
- Interpreting scale as time.
- Unified intra- and inter-scale modeling.
- Explicit steerability.
Why introduce time t in generative models from a traditional perspective?
Generative models for continuous data (such as images), such as Flow matching and Diffusion, essentially solve a mathematical problem: how to map a simple, known prior distribution (such as a Gaussian distribution) to a complex, high-dimensional data distribution (such as a real image distribution). In this process, the role of introducing the time variable is to break down a difficult, one-step non-linear mapping into an infinite (or large) number of simple, local transformations in a continuous space (which can be linear or non-linear, but simple enough). Here, is the coordinate axis that describes the continuous process (trajectory).
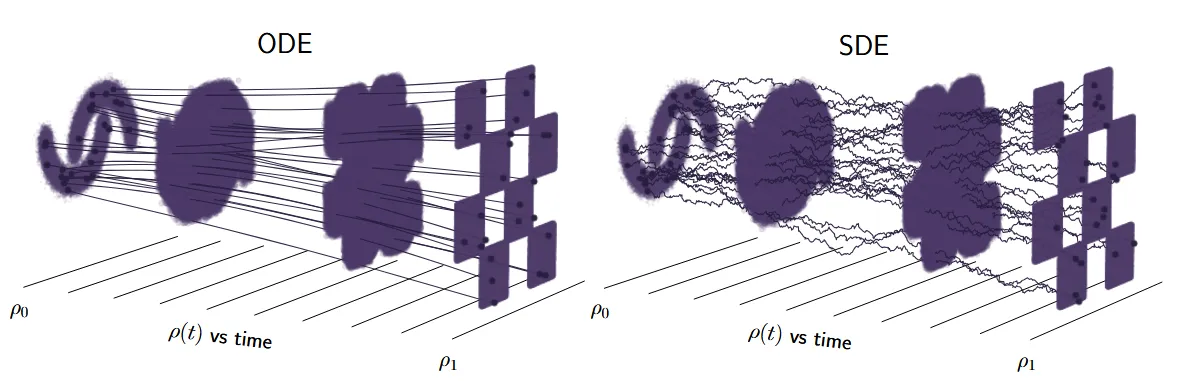
But we rethink the concept of “time” in flows.
The model learns to transport a simple distribution along a continuous-time axis to the data distribution, but this axis need not explicitly correspond to the true structure (hierarchy) of the data. Using images as an example, we can see that an image’s global composition and local textures are not the same, and we can roughly partition them, but the model might not be able to do this task. Moreover, theoretically, for scientific data (e.g., small molecules, protein structures), structures at different scales should not be treated equally by the same noise scheduler.
Therefore, we believe that existing generative models lack a multi-scale control method rooted in the essence of the generation path, particularly lacking the ability to “preserve structures at certain frequencies while only modifying structures at other frequencies.” K-Flow can reinterpret the “time dimension” of the flow as the “traversal order in the scale space,” thereby aligning the generation process with the hierarchical structure of the data itself.
Note that this step is not simply changing the formulation of the time dimension . Our modeling object has also shifted from “how loud the noise is at a certain moment” to “which scale of information the model is processing at the current stage.” Once we align the traditional generation process defined by the “time axis” with the concept of “scale,” which has explicit physical meaning, the generation path is no longer an uninterpretable and uncontrollable black box.
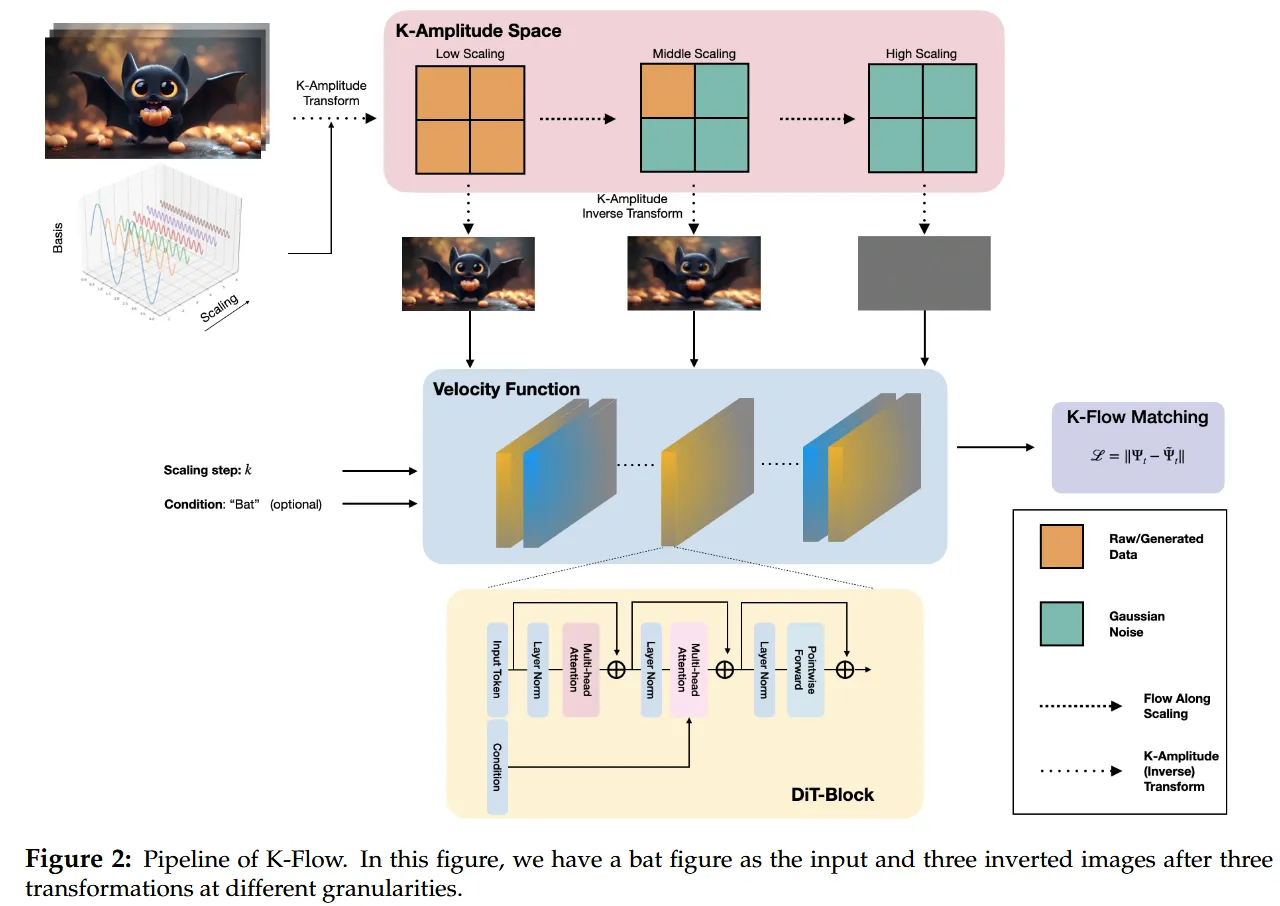
Frequency is just a starting point; energy is the essence.
We propose in the K-Flow paper that this amplitude is not merely a mathematical norm but also a representation of the data’s energy at each scale. In physics, energy is proportional to the square of the amplitude. Because of this, K-Flow emphasizes that the amount of information and the energy distribution across different scales are uneven, and that the generation path should also follow this uneven pattern.
Frequency merely indicates which bands the information has been divided into; energy tells us which bands deserve more modeling resources, which bands fundamentally determine the skeleton, and which bands determine the details, etc. From this point, many worthwhile follow-up research projects can be derived, including but not limited to multiple important directions such as generative model training efficiency, inference efficiency, steerable generation, and multi-modal control.
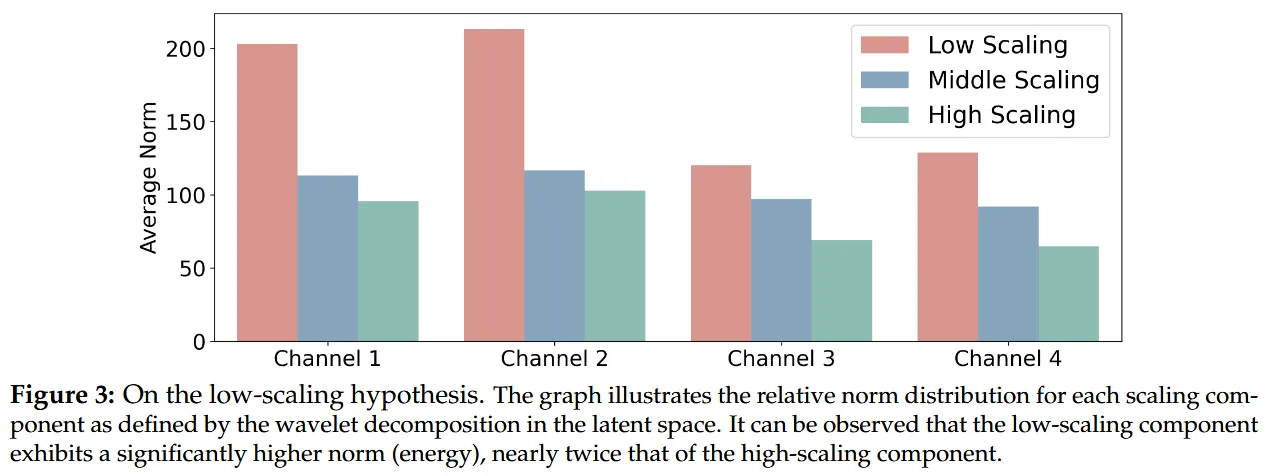
The small experiment on the latent space in the paper is also very intuitive. Under wavelet decomposition, the average norm of the low-scale components is significantly higher than that of the high-scale components, even approaching twice that of the latter. This means that the low-scale part often carries more dominant structural information. This aligns well with the objective law of natural images (1/f): as (amplitude) (which can be understood here as frequency) increases, the amplitude and energy will rapidly decay. This implies that the low-frequency components contain the vast majority of the information content and energy in a signal. Even if the image data is highly compressed in the latent space, this 1/f-like scaling unevenness, with “high low-frequency energy, low high-frequency energy,” still persists. (This actually suggests a direction for future work: guiding the resource allocation of generative models to produce more high-quality images per unit time, based on the concepts of frequency, energy, and multi-scale.)
From this perspective, K-Flow goes a step further than many works that merely use the concept of the “frequency domain” as a form of regularization to improve generative models.
What exactly does K-Flow do?
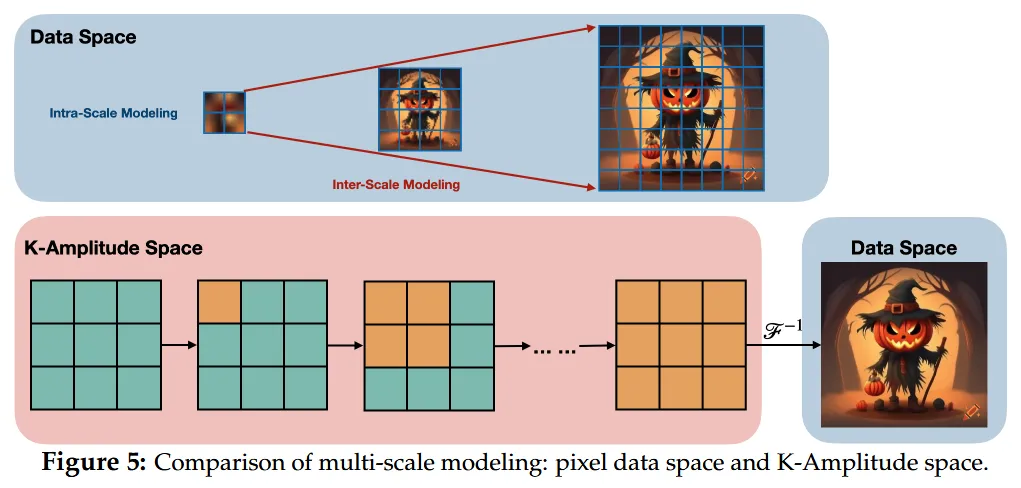
The core of K-Flow can be summarized in one sentence: first move the data into the K-amplitude space, then flow along the scale, and finally return to the original space to perform matching.
The paper used three examples: Fourier, Wavelet, and PCA. Fourier provides the classic frequency domain, Wavelet provides a representation that combines scale locality and spatial locality, and PCA offers a data-dependent decomposition method. In other words, the essence of K-Flow is not “wavelet flow” or “Fourier flow,” but a more general framework. If we can decompose the data into an ordered set of scale components, and this transformation is invertible, K-Flow can work. This grants K-Flow immense flexibility and can be considered a fundamental innovation at the paradigm level.
It must be emphasized that the vector field learned by K-Flow at the current scale is localized. That is to say, at a given generation stage, the model primarily focuses on the current small band rather than processing all information in the entire space simultaneously. This “local update, piece-by-piece advancement” approach, on the one hand, gives the model a clearer sense of hierarchy, and on the other hand, creates conditions for controllable generation. During the generation process, we can discuss “what content is being modified in this segment,” rather than just broadly saying “the model is continuing to denoise.”
This is also where K-Flow differs from some existing multi-scale generation works. Although related to works like WaveDiff and VAR, K-Flow is not restricted to specific paradigms like wavelet latent or next-scale prediction. Our ultimate goal is to make K-Flow itself the first principle of generative modeling.
Controllability exists within the generation path.
Many generative models can achieve “multi-scale” generation, such as cascaded diffusion, VAR, and other works, but the highlight of K-Flow is that it turns controllability into an inherent property of the path itself, rather than an engineering trick added after the fact.
Our paper also includes a very representative experiment where, in class-conditional generation, we only retain the class condition in the earlier scale segments and drop it in the later scale segments. The result is that K-Flow, even after dropping the class condition during the last 70% of the scaling steps, can still relatively well preserve high-frequency details; in comparison, normal latent flow matching is more prone to blurring the entire image. This indicates that in K-Flow, different stages genuinely undertake different levels of information processing, rather than mixing all semantics and details together.

Even more intuitive are the scaling-controllable generation figures. When fixing the high-scale noise, the faces generated by the model will retain similar local details such as eyes, noses, and eyebrows, while low-scale context like background, age, and hairstyle will change; conversely, when fixing the low-scale noise, the background and overall attributes remain more stable, while high-resolution expressions and appearance details can be edited. In other words, K-Flow is not “supporting control” in an abstract sense, but rather visually demonstrating “what belongs to the low scale and what belongs to the high scale” for us to see.


This matter is especially crucial for text-to-image generation. From a higher-level perspective, the text condition does not necessarily need to act in exactly the same way and with the same intensity throughout the entire generation process. The paper has already provided a signal worth amplifying in the class-conditional experiment: category labels are closer to low-scale information, and different scale components hold the promise of being influenced by different caption information in the future. Following this line of thought, the most attractive aspect of K-Flow for text-to-image generation is not “replacing one scheduler with another,” but providing an opportunity to reorganize the relationships between text semantics, image structures, and texture details.
What do the experimental results indicate?
Looking at the results, K-Flow has at least proven one thing: this is not just a “conceptually beautiful” story. The paper shows that on CelebA-HQ 256, the wavelet version of K-Flow achieved an FID of 4.99, outperforming latent flow matching with the same backbone (5.28) and WaveDiff (5.94); on LSUN Church 256, the three-scale wavelet K-Flow reached 5.19 FID / 0.49 Recall, also outperforming the corresponding LFM baseline (5.54 / 0.48). In ImageNet class-conditional generation, the Fourier version with CFG reached an FID of 2.77, basically on par with LFM’s 2.78, but with a lower CDR (1.49 vs. 3.25), indicating that it has a better sense of scale regarding whether “the condition should run through the whole process.” Moving towards scientific tasks, on the molecular assembly of COD-Cluster17, K-Flow also consistently surpassed baselines like AssembleFlow across three data scales, achieving a PM-center of 6.07 on the full set, whereas AssembleFlow scored 6.21.
Below are some of our results:
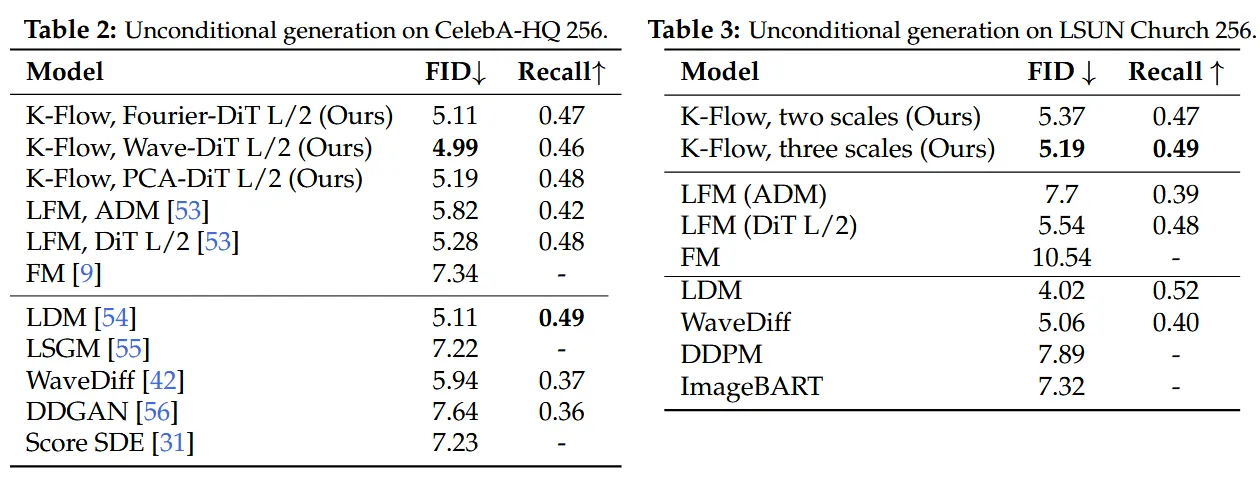
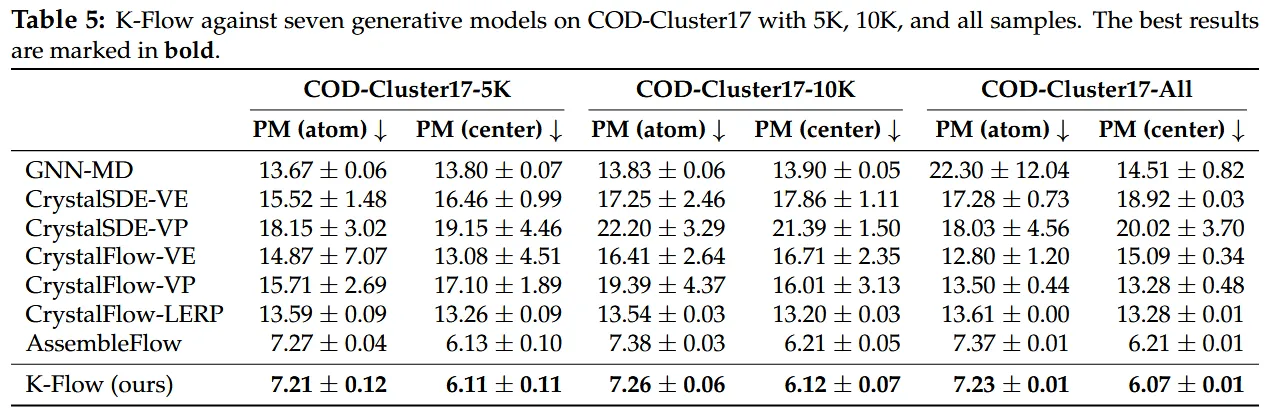
These results may not mean that the current version of K-Flow is the ultimate answer, but they at least show that what it has grasped is solid: placing the generation process in the K-amplitude space indeed yields more natural multi-scale modeling, clearer controllability, and the potential to extend to scientific scenarios beyond images.
If you feel this work has inspired or helped you, you are welcome to cite our paper!
@inproceedings{du2026flow,
title={Flow Along the \$K\$-Amplitude for Generative Modeling},
author={Weitao Du and Jiasheng Tang and Shuning Chang and Yu Rong and Fan Wang and Shengchao Liu},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={<https://openreview.net/forum?id=O224NIizhz>}
}